

Если необходимо рассчитать статистики для большой выборки, то сначала необходимо построить вариационный ряд. Для этого необходимо вызвать изменюAnalysis → StartupPanel
Появится окно Основных статистик и Таблиц. Нужно вызвать процедуру Frequencytables.
| 
|
Появится окно с одноименным именем.

Нужно выбрать необходимую переменную, по которой будете строить вариационный ряд (D).
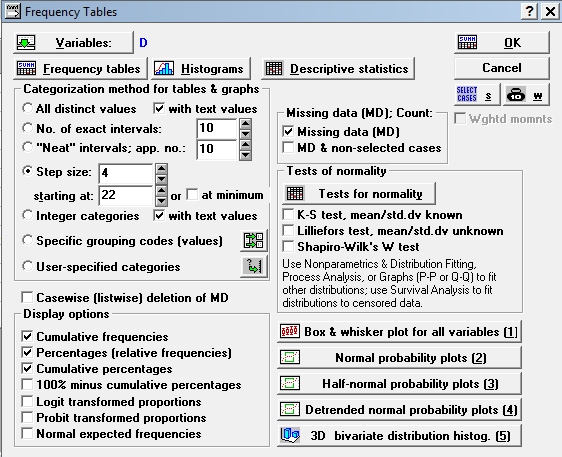
Необходимо заполнить следующие поля в окне.
| Название поля | Пояснения |
| Step size | Величина разряда |
| Starting at | Нижнее действительное значение первого класса |
| Atminimum | Снимите отметку в данном поле |
Нажать OK.
В итоге получили таблицу вариационного ряда по выбранной переменной.
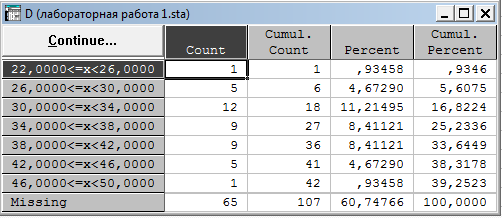
| Графы таблицы вариационного ряда | Пояснения |
| 1 графа | Действительные границы классов |
| 2 графа Count | частота |
| 3 графа | Накопленная частота |
| 4 графа | Частота в процентах |
| 5 графа | Накопленная частота в процентах |
Расчет основных статистик для сгруппированного ряда
Бывают ситуации, что исследователь имеет уже сгруппированные данные, поэтому надо получить статистики для большой выборки. Это данные в графах 7 и 8 (Ступень толщины и частота).
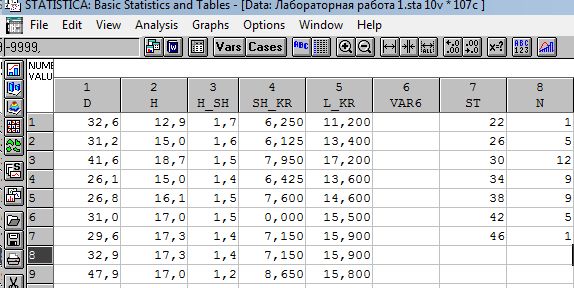
Для расчета статистик по сгруппированному ряду необходимо в окне Descriptivestatistics выбрть переменную по которой необходимо рассчитать статистики. Далее нажмите клавишу W (вес).
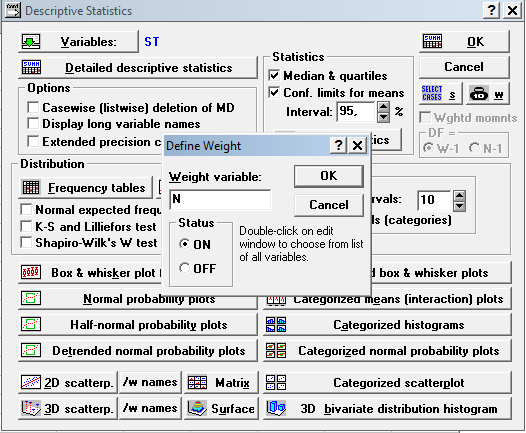
ПоявитсяокноDefineWeight. ВполеWeightvariable: введите переменную, которая определяет встречаемость данного класса (N (частота)). ОК.
ЗатемнужнонажатькнопкуDetailedDescriptivestatistics.

Построение Гистограммы
Необходимо нажать накнопкуHistogramsвокнеFrequencytables. Получим график Гистограмма по выбранной переменной.
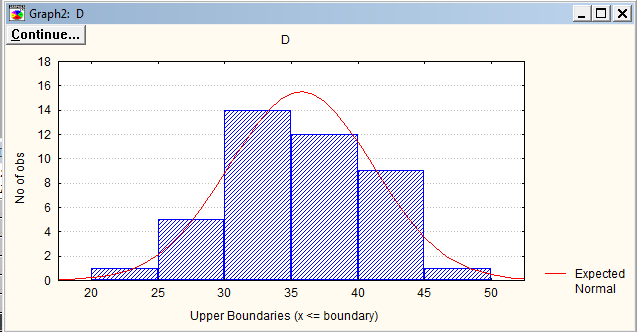
Для того чтобы сделать необходимые подписи на русском языке нужно нажать правой клавишей мыши на названии оси и выберите шрифт MS Sans Serif и подписать необходимые оси и заголок графика в окне EditTitles.
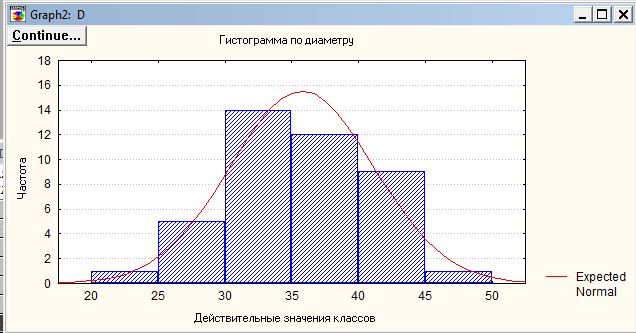
Графический анализ данных
Построение графика зависимости между двумя переменными
Вызовите команду Graphs→Scatterplots. В появившемся окне 2DScatterplotsвведите переменные (Variables), которые будут осями Х и У.
ОК. Получился график зависимости.
Имеется возможность редактировать свойства графика, для этого необходимо встать на ось и вызвать контекстное меню (нажать правую клавишу мыши):
Изменение шрифта названия, осей;
Изменение градуировки шкал осей
Для подписи точек, необходимо выделить любую точку, нажать правую клавишу мыши и выбрать в появившемся окне Properties (Свойства).
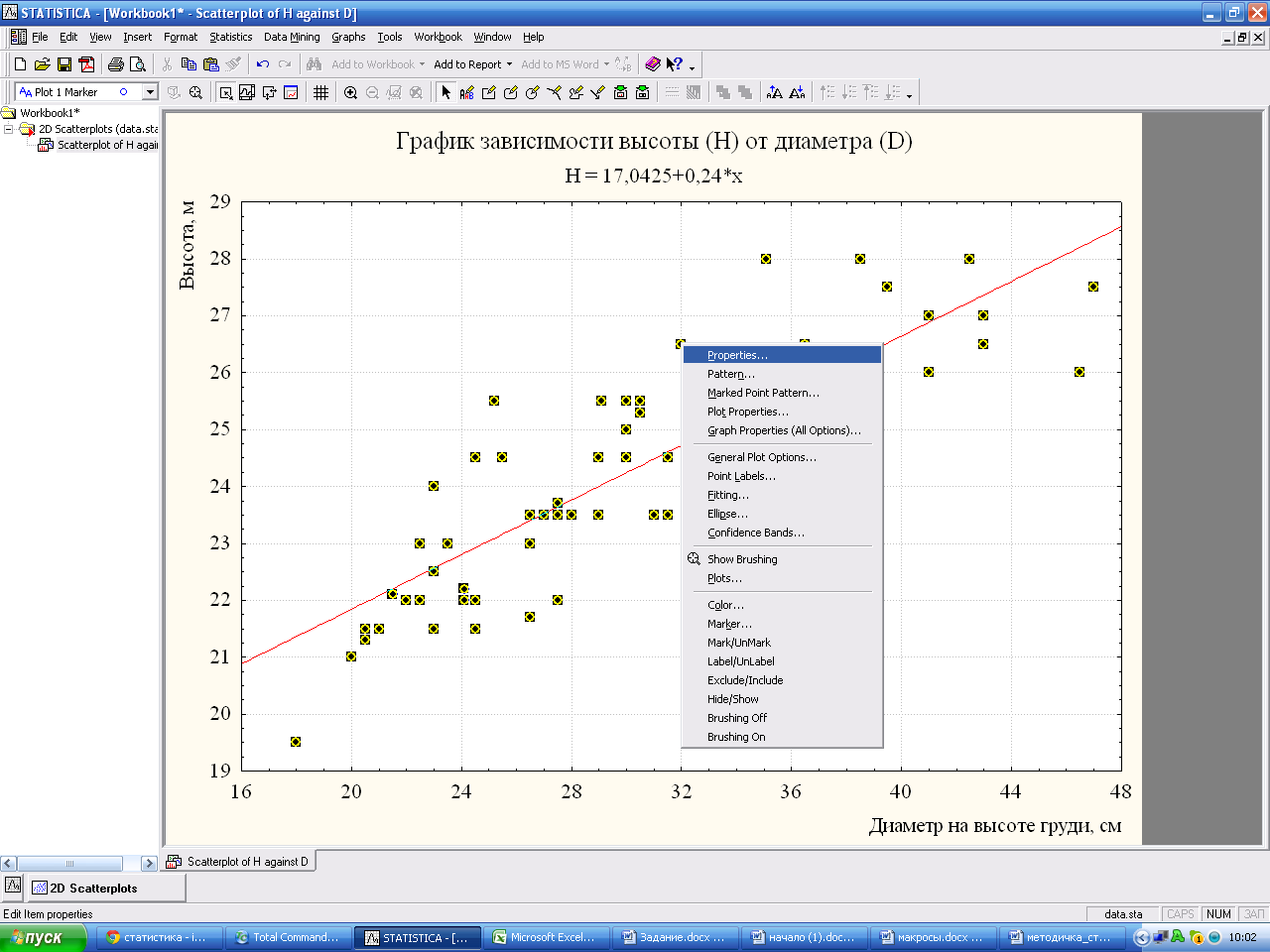
Настройте, как нужно. В результате получится
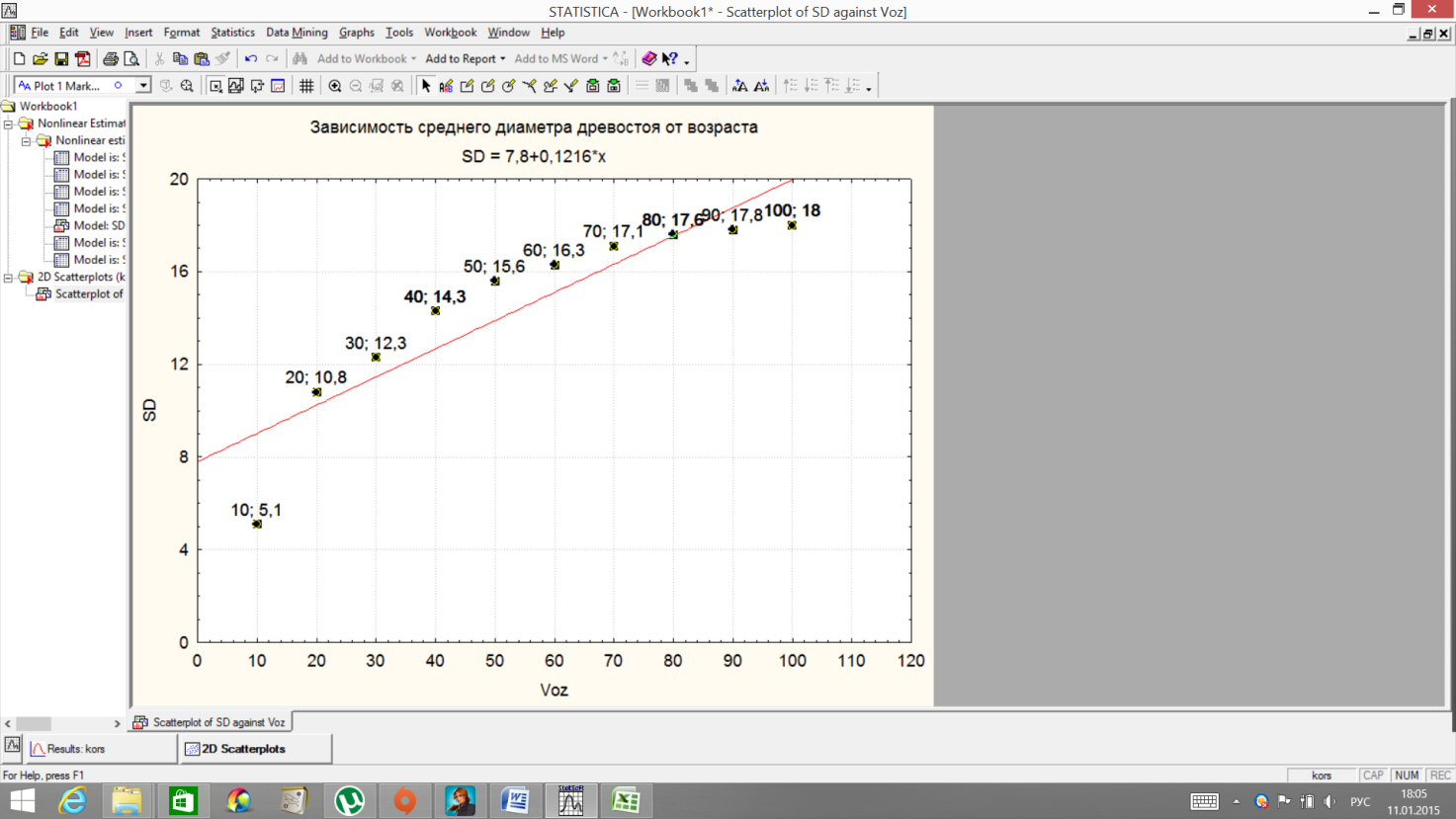
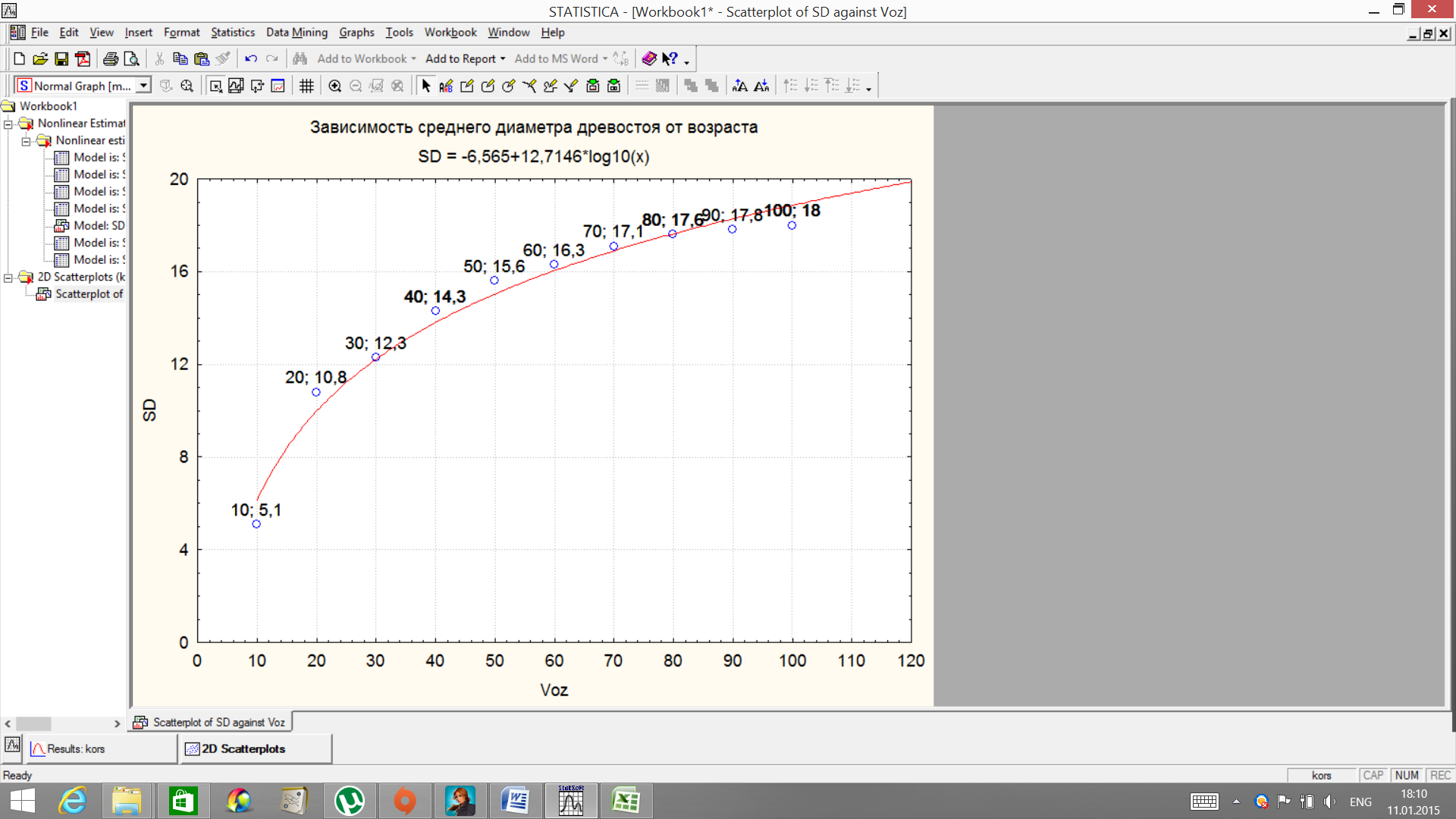
Измените форму выравнивающей зависимостиAllOptions - Plot: Fitting, выбрав необходимую форму зависимости.
3.2. Построение графика зависимости между тремя переменными (3Dграфика)
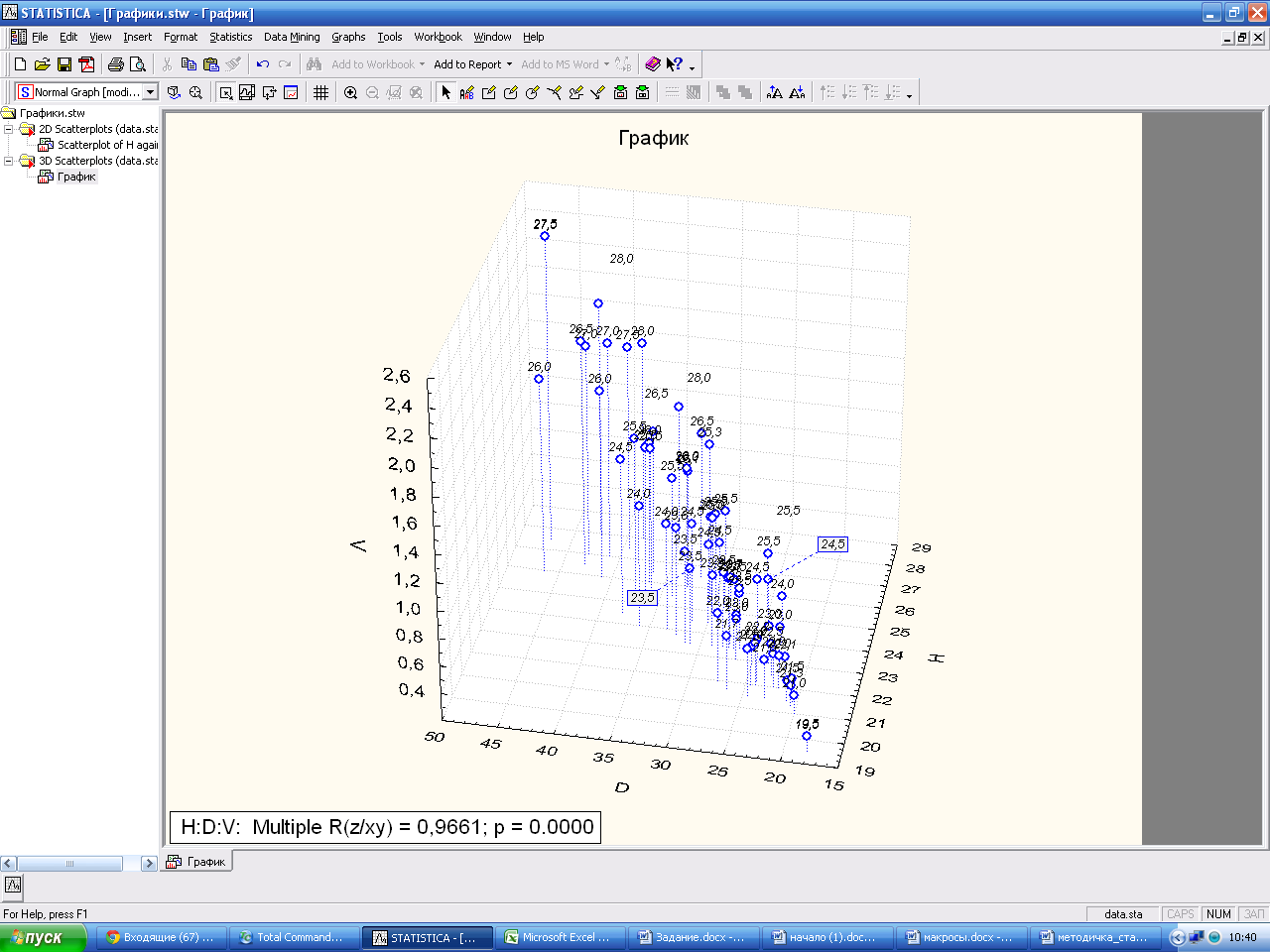
Выполните команду Graphs→3DXYZGraphs→Scatterplots..
Заполните поля с данными. ОК.
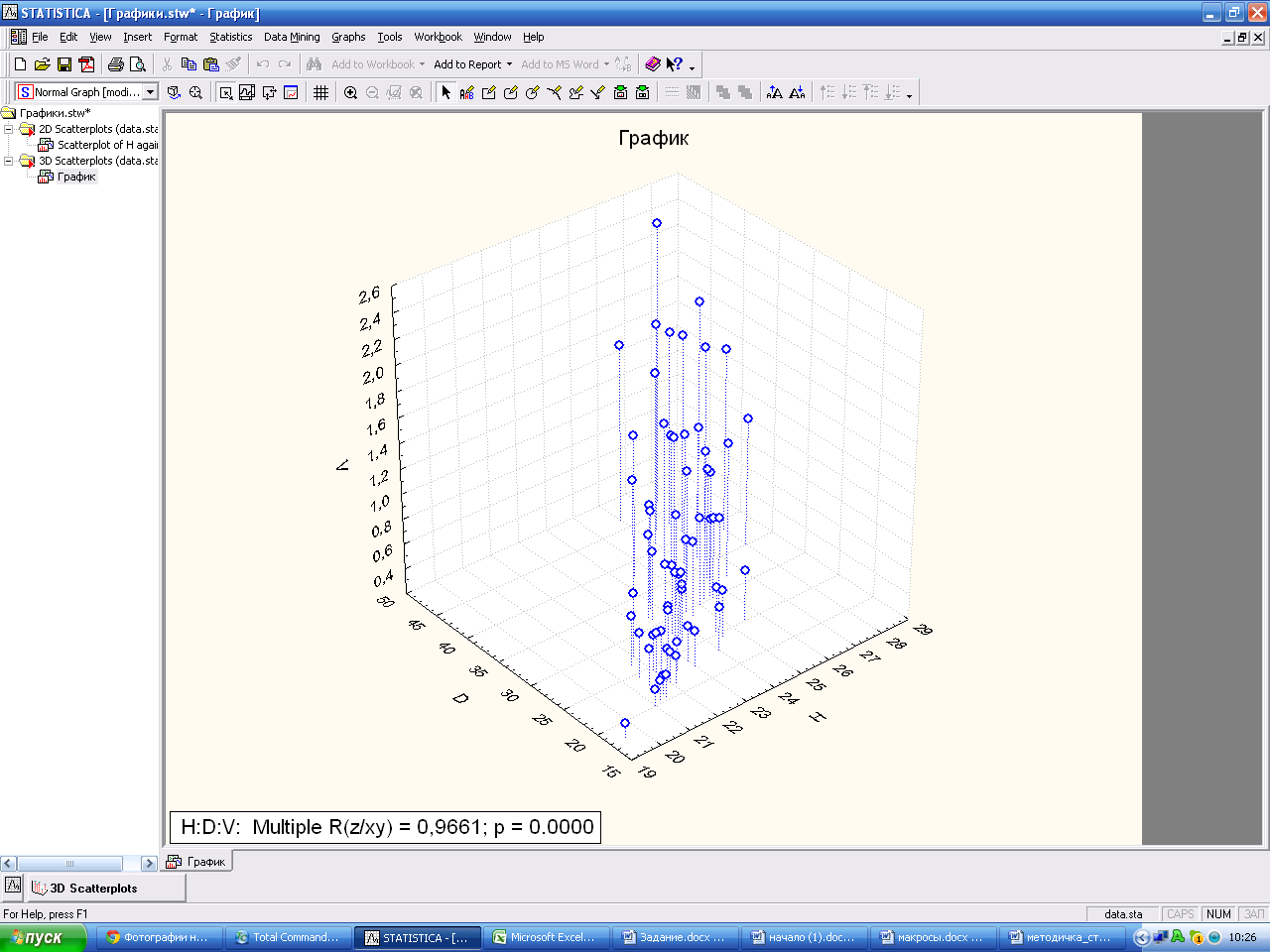
Для выбора нужного ракурса нажмите кнопку 3DRotationcontrol (3Д контроль поворота).
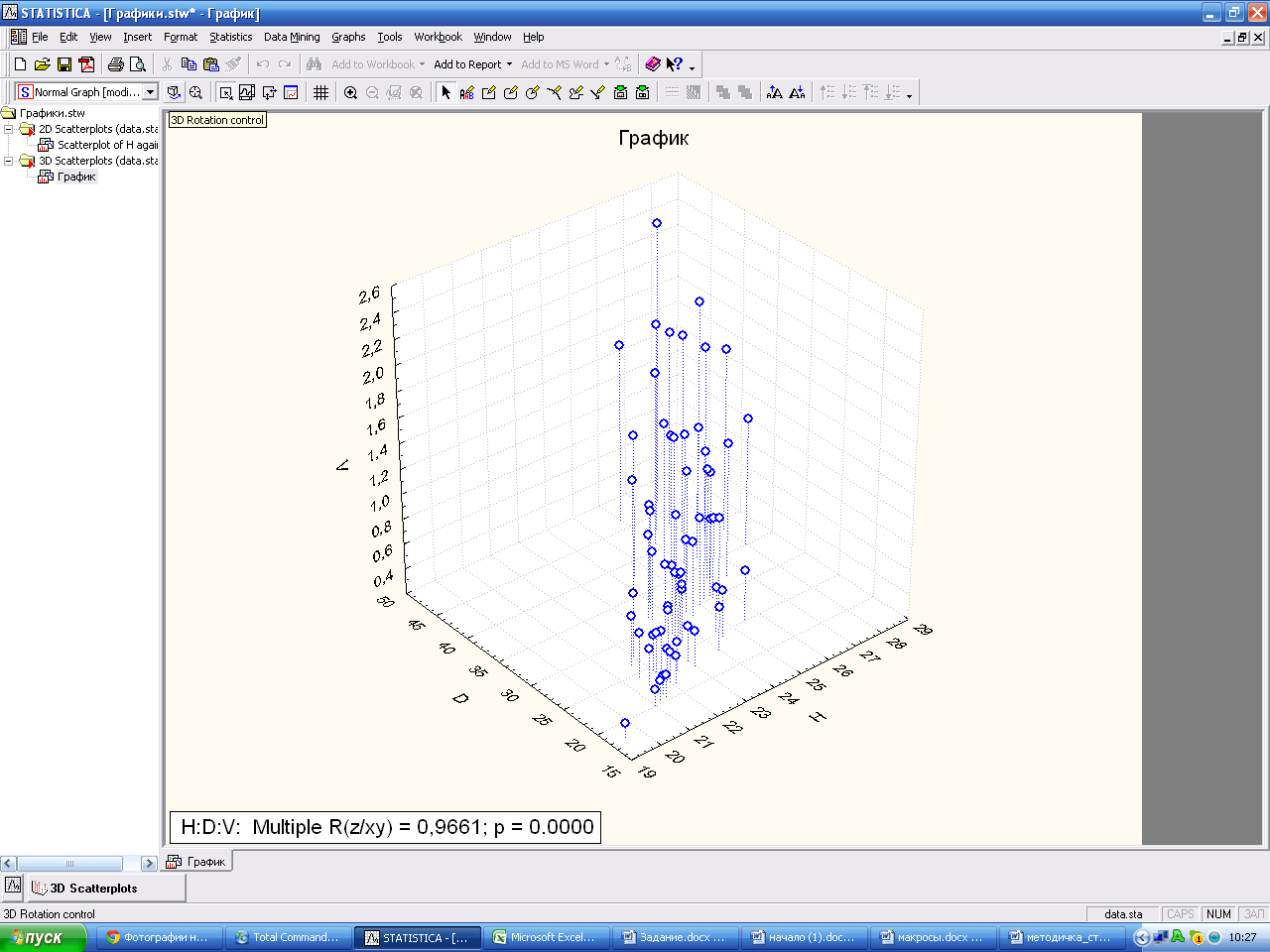
Используя клавиши изменения угла поворота по оси ОХ и ОУ пользователь настраивает нужный ракурс графика, двигая ползунки.
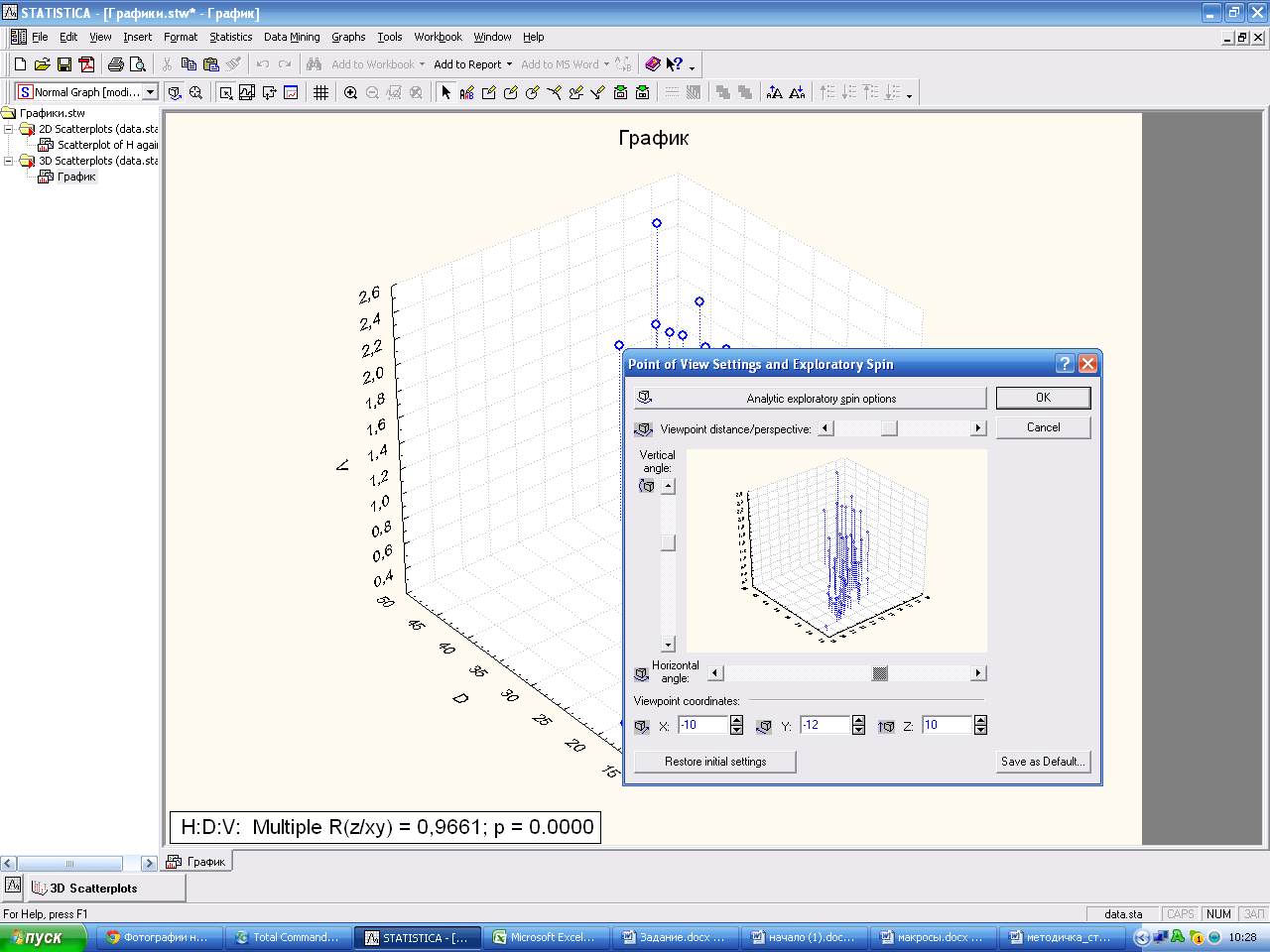
Итоговый вид графика. Настройте все опции.
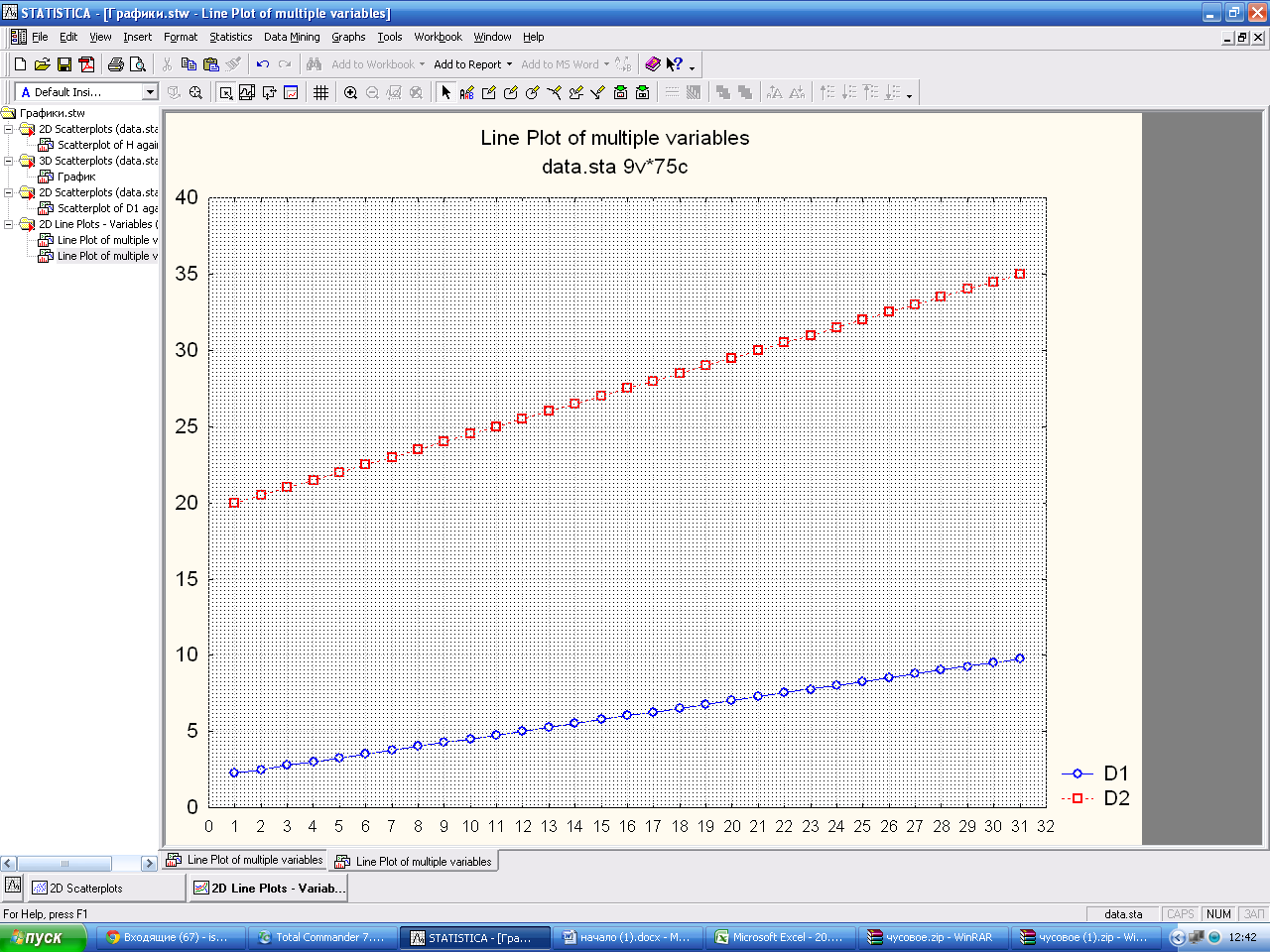
Построение графиков двух зависимостей
Выполните команду Graph - Scatterplots. ВыберитеGraphtype (Типграфика) - Multiple (Множественный). Выберите оси ОХ и ОУ переменными. Используется, если разный разбег у векторов данных.
Проверка статистической гипотезы
Этапы
Сформировать проверяемую H0 и альтернативную H1 гипотезы
1. Назначить уровень значимости α
2. Выбрать статистику Z критерия для проверки гипотезы H0
3. Определить выборочное распределение статистики Z критерия при условии, что верна гипотеза H0
4. Определить критическую область Vk в зависимости от формулировки альтернативной гипотезы одним из неравенств
5. Получить выборку наблюдений и вычислить значение критерия Xв
6. Принять решение
В статистических пакетах (таких как Статистика) обычно в прямом виде критерий значимости α не задается. В анализах выдается значение вероятности того, что случайная величина Z (если гипотеза H0 верна) превышает Zв :
Вероятность называется p-значением ( p-level )
Если P>α , нулевая гипотеза принимается. Если P<α , нулевая гипотеза опровергается.
Пример:
Проверить гипотезу, что варианты описываются нормальным распределением. (Распределение по диаметру). Принять α=0,05.
В пакете Статистика выбирается Statistics →DistributionFitting (Подбор распределений). Далее в появившемся окне выбирается ContinuousDistributions (Непрерывные распределения), нормальное – Normal.
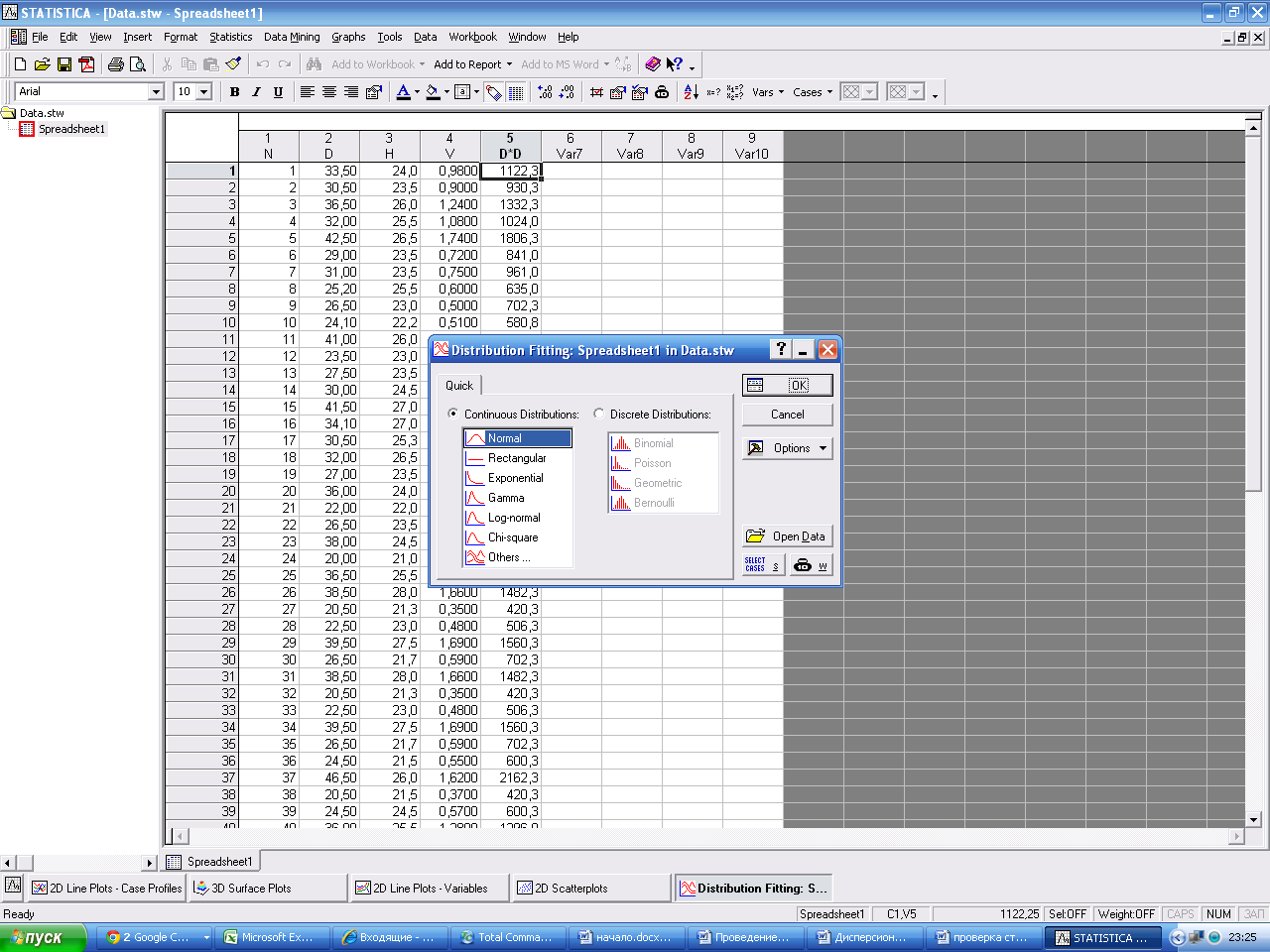
ОК.
В окне FittingContinuousDistributions в поле Variables введите имя переменной по которой будете проводить анализ. На закладке Parameters (Параметры) программа рассчитает среднее (Mean) и дисперсию (Variance).
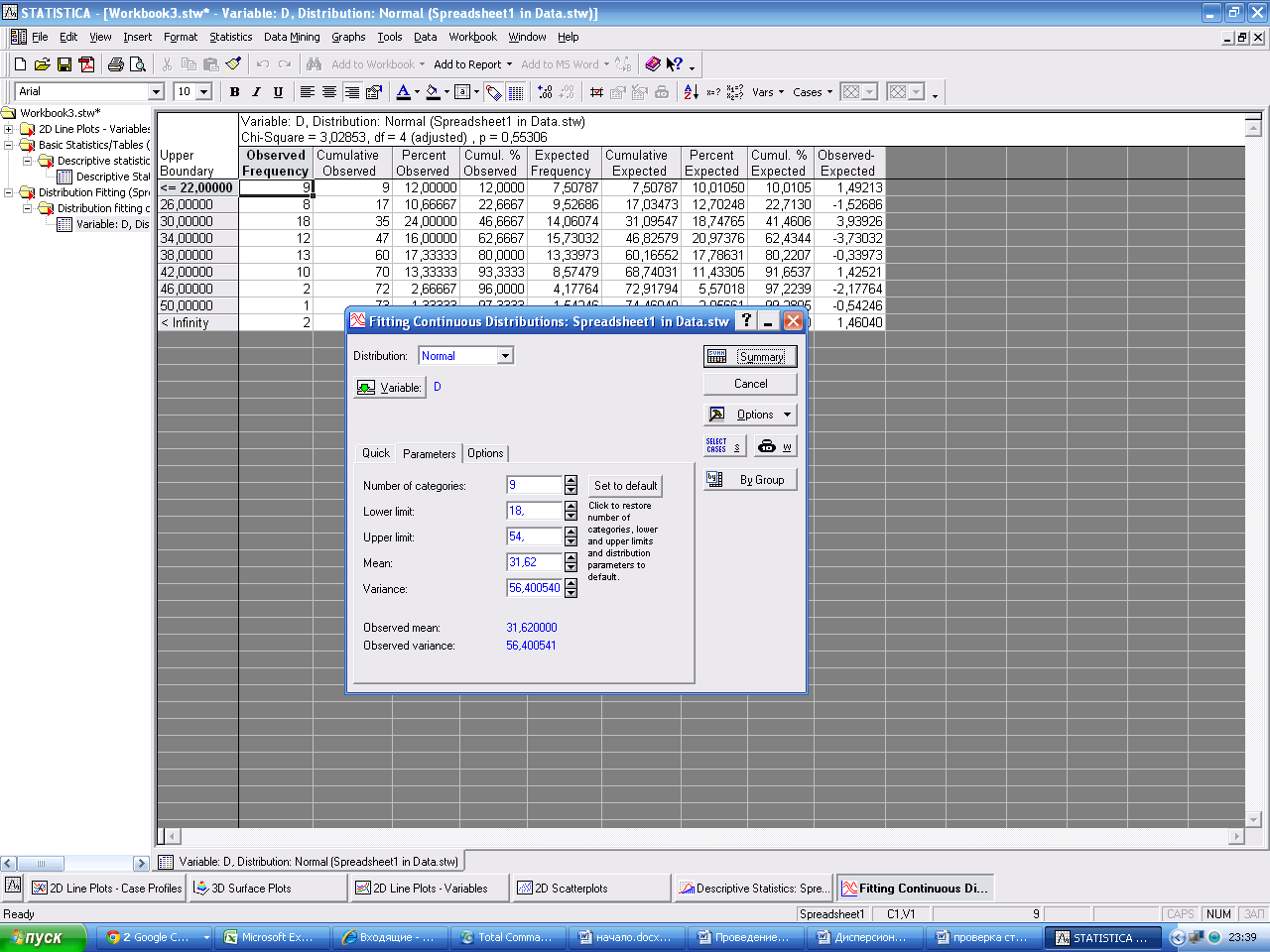
По умолчанию, количество интервалов равно 10. Его можно изменить. Нажмите Summary.
На экране появится таблица расчета.
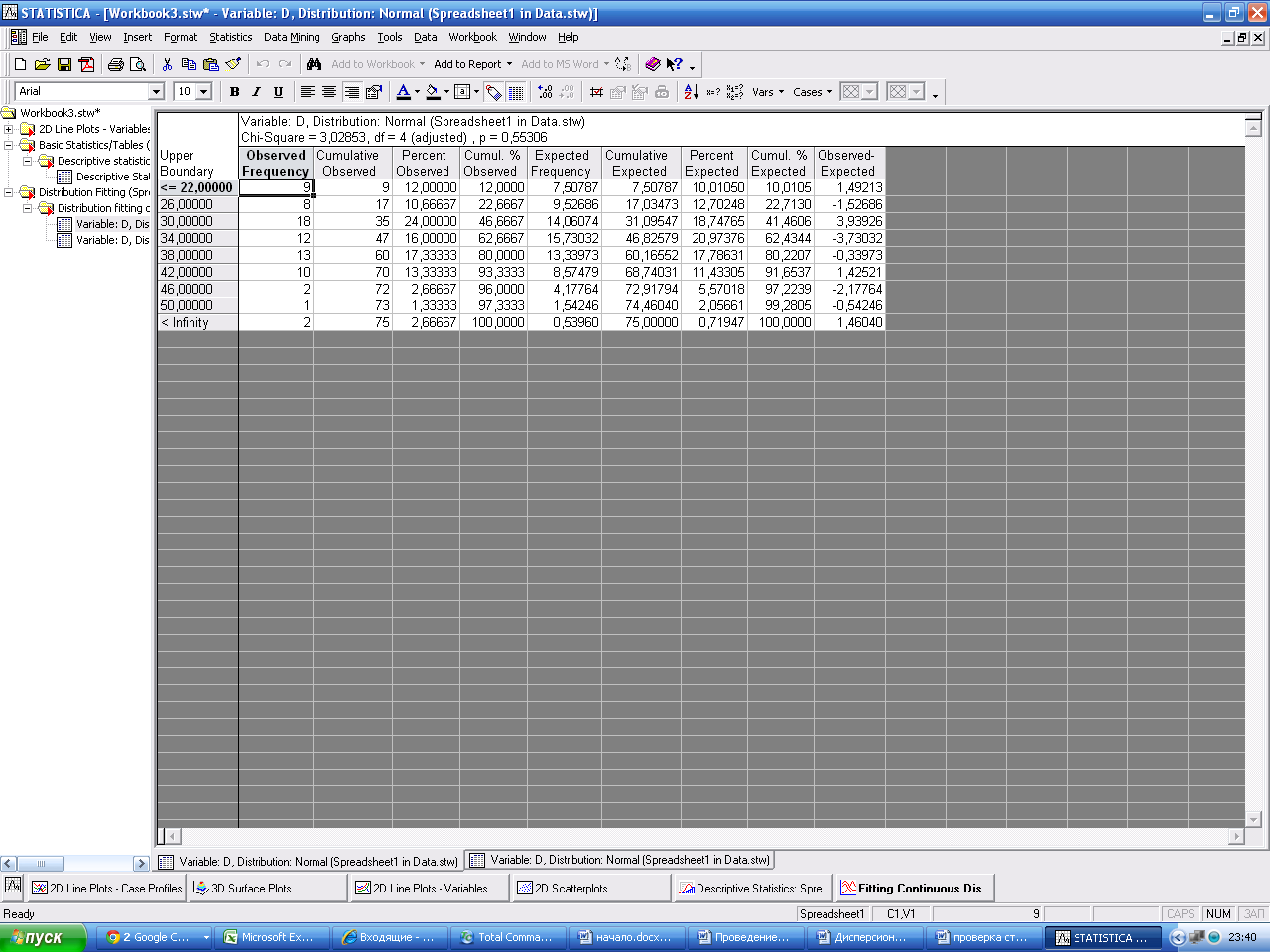
χ2выч=3,02, число степеней свободы df=4, вычисленное значение вероятности p=0,553.
В результате, вычисленное значение уровня значимости значительно превышает заданный уровень значимости 0,553 > 0,05, то гипотезу, что наша переменная описывается нормальным законом распределения принимается.
Работа _
1. Вычислить доверительные интервалы для среднего и дисперсии нормально распределенной генеральной совокупности при α=0,05;
2. Проверить гипотезы H0:X=X0, где X0=X+0,5S